
Its Day 96 of my 100 Days of Cloud journey and in todays post we’ll take a quick look at Azure Chaos Studio and how it can test resiliency in your resources.

Before we delve into the capabilities of Azure Chaos Studio, lets take a step back and define Chaos Engineering and look at some examples of where this would have been useful traditionally.
Chaos Engineering
Chaos Engineering is one of the trending topics in the industry at present, and the ability to test resiliency in deployments is one of the most important steps you will take in ensuring that your Resources will scale correctly or recover from unforseen events such as high loads or unexpected loss of a cluster node.
I’m going to use one of my favourite examples to illustrate this, and thats an on-premises Exchange installation running in a highly available DAG configuration:
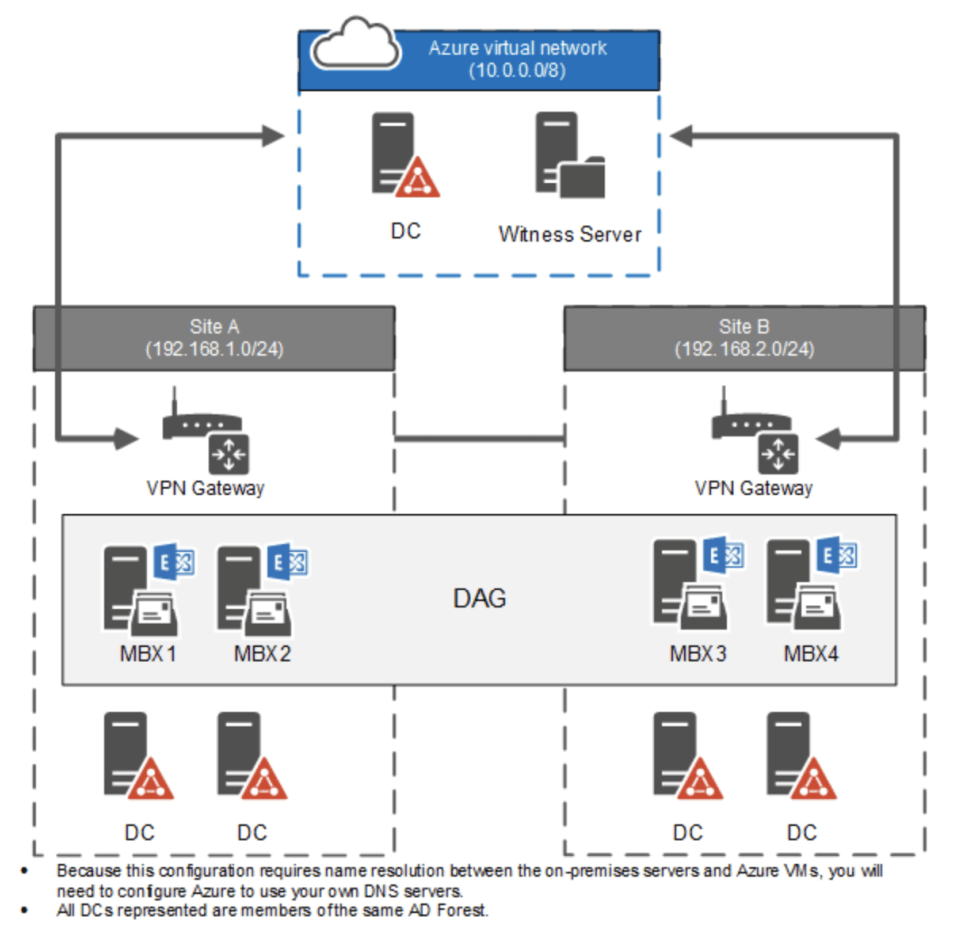
This is a standard DAG configuration with 2 Exchange Servers on each site, and a cloud Witness Server in Azure. There are also 2 Domain Controllers in each site and a DC located in Azure.
Lets assume that we have a mailbox database on each of the servers, and lets also assume that replication of the databases follow this pattern:
- MBX1 replicates a copy to MBX3
- MBX2 replicates a copy to MBX4
- MBX4 replicates a copy to MBX1
- MBX3 replicates a copy to MBX2
There are a number of scenarios here with the potential for failure, such as:
- What if one of the Exchange Servers fails and the database fails over so that 2 Databases run on a single server, can that server manage the load?
- What if one of the sites fails in it entirety? Will the single site handle both server load and network load?
- What if the DAG Network fails and the sites can’t talk to each other so no replication occurs? Will the Witness Server handle the cluster communications?
- What if the Site A network fails? Will the Witness Server bring up all of the databases on Site B. What happens when Site A comes back up and the servers on that site still think they are hold the “Live” databases?
- What if the Domain Controllers fail? Will the users whose email is hosted on databases on the site where the DC’s have failed be able to authenticate?
All of the above are real scenarios that could happen. And thats where Chaos Engineering comes in. It is defined as:
the ability to deliberately inject faults that cause system components to fail. The goal is to observe, monitor, respond to, and improve your system’s reliability under adverse circumstances. For example, taking dependencies offline (stopping API apps, shutting down VMs, etc.), restricting access (enabling firewall rules, changing connection strings, etc.), or forcing failover (database level, Front Door, etc.), is a good way to validate that the application is able to handle faults gracefully.
High Availability is no guarantee that a service cannot fail, and designing your service to expect failure is a core approach to creating services and applications. Chaos Engineering strives to anticipate rare, unpredictable, and disruptive outcomes, so that you can minimize any potential impact on your customers.
Azure Chaos Studio
But all of that testing isn’t a problem for you though because you’ve moved to Azure! And you configured cool stuff like Geo-redundant Storage, Virtual Machine Scale Sets and Azure Site Recovery between regions! So all of your stuff is safe, right?
Wrong. And if you haven’t managed to fully test the resiliency of your cloud-based resources, thats where Azure Chaos Studio can help!
Chaos Studio enables you to orchestrate fault injection on your Azure resources in a safe and controlled way and this is done by using a chaos experiment, which describes the faults that should be run and the resources those faults should be run against.
Chaos Studio supports 2 types of faults:
- Service-direct faults, which run directly against an Azure resource without any installation or instrumentation (for example, rebooting an Azure Cache for Redis cluster or adding network latency to AKS pods)
- Agent-based faults, which run in virtual machines or virtual machine scale sets to perform in-guest failures (for example, applying virtual memory pressure or killing a process).
Each fault has specific parameters you can control. Lets take VM Scale Sets as an example – you have created an application that runs on VMs in a scale set and have configured this as follows:
- Minimum of 2 VMs, Maximum of 10 in the scale set
- Additional VM is created if:
- CPU hits 90%
- Memory hits 80%
But have you ever tested that this actually works? In Chaos Studio, you can import your Scale Set and then create an “Experiment” to apply specific faults to the scale set. We can see that there are a number of faults that are available to choose from:

We can also see that we have the concept of Steps and Branches. When you build an experiment:
- You define one or more steps that execute sequentially, and each step containing one or more branches that run in parallel within the step.
- Each branch contains one or more actions such as injecting a fault or waiting for a certain duration.
- Finally, you organize the resources that each fault will be run against into groups called selectors.

When you run your expirement, you will see output around each fault and the results of each of the steps:

The benefits of Chaos Studio experiments on your infrastructure are:
- Familiarize team members with monitoring tools.
- Recognize outage patterns.
- Learn how to assess the impact.
- Determine the root cause and mitigate accordingly.
- Practice log analysis.
Conclusion
So thats an overview of Chaos Engineering and how Azure Chaos Studio can help test for faults in your resources and build resiliency into your applications. You can find more details on Azure Chaos Studio here.
Hope you enjoyed this post, until next time!
