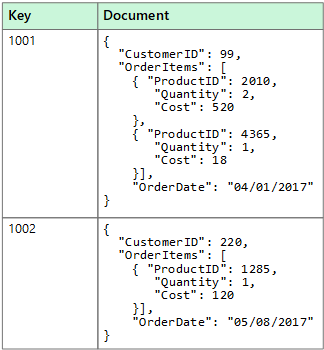
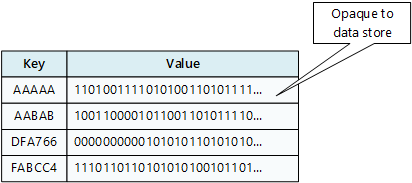
Its Day 64 of my 100 Days of Cloud journey, and today I’m looking at Azure Cosmos DB.

In the last post, we looked at Azure SQL and the different options we have available for hosting SQL Databases in Azure. SQL is an example of a Relational Database Management System (RDBMS), which follows a traditional model of storing data using 2-dimensional tables where data is stored in columns and rows in a pre-defined schema.
The opposite to this is non-relational databases, which use a storage model that is optimized for the specific requirements of the type of data being stored. Non-relational databases can have the following structures:
- Document Data Stores, which stores data in JSON, XML, YAML or plain text format.
- Columnar Data Stores, which stores data in column families which are logically related and manipulated as a unit.
- Key/value Data Stores, which holds a data value that has a corresponding key.
- Graph Databases, which are made up of nodes and edges to host data such as Organization Charts and Fraud detection.
All of the above options can be achieved by using Azure Cosmos DB.
Overview
Lets start with an overview – Azure Cosmos DB is a fully managed NoSQL database provides high availability, globally-distributed access to data with very low latency
If we log on to the Azure Portal and go to create an Azure Cosmos DB, we are given the options below:
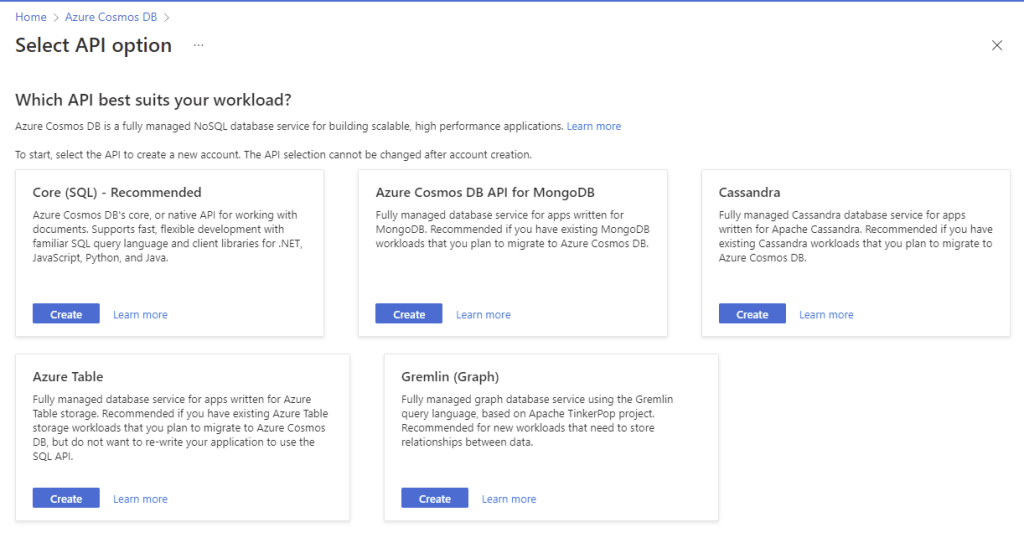
The different API’s available are:
- Core (SQL) API: Provides the flexibility of a NoSQL document store combined with the power of SQL for querying.
- MongoDB API: Supports the MongoDB wire protocol so that existing MongoDB client continue to work with Azure Cosmos DB as if they are running against an actual MongoDB database.
- Cassandra API: Supports the Cassandra wire protocol so that existing Apache drivers compliant with CQLv4 continue to work with Azure Cosmos DB as if they are running against an actual Cassandra database.
- Gremlin API: Supports graph data with Apache TinkerPop (a graph computing framework) and the Gremlin query language.
- Table API: Provides premium capabilities for applications written for Azure Table storage.
The key to picking an API is to select the one that best meets the needs for your database, but be warned: if you pick an API you cannot change it afterwards. Each API has its own set of database operations. These operations range from simple point reads and writes to complex queries. Each database operation consumes system resources based on the complexity of the operation.
Once your API is selected, you get into the usual screens for creating resources in Azure:
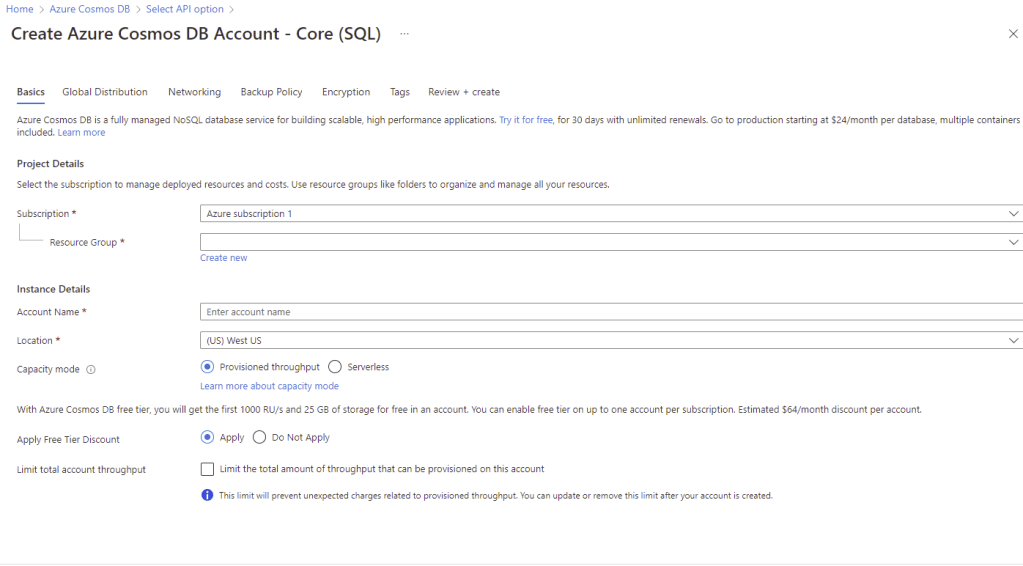
Pricing
Now this is where we need to talk about pricing – in SQL, we are familiar with licensing using Cores. This works the same way in Azure with the concept of vCores, but we also have the concept of Database Transaction Units (DTU’s) which is based on a bundled measure of compute, storage, and I/O resources.
In Azure Cosmos DB, usage is priced based on Request Units (RUs). You can think of RUs per second as the currency for throughput. As shown in the screenshot above, there are 2 pricing models available:
- Provisioned throughput mode: In this mode, you provision the number of RUs for your application on a per-second basis in increments of 100 RUs per second. You are billed on an hourly basis for the number of RUs per second you have provisioned.
- Serverless mode: In this mode, you don’t have to provision any throughput when creating resources in your Azure Cosmos account. At the end of your billing period, you get billed for the number of Request Units that has been consumed by your database operations.
We also have a 3rd option:
- Autoscale mode: In this mode, you can automatically and instantly scale the throughput (RU/s) of your database or container based on its usage, without impacting the availability, latency, throughput, or performance of the workload.
Each request to Azure Cosmos DB returns used RUs to you so you can decide whether stop your requests or increase the RU limit on the Azure portal.
Consistency Levels
The other important thing to note about Cosmos DB is Consistency Levels. Because Cosmos DB is a globally distributed database, you can set the level of consistency for replication across your global data centers. There are 5 levels to choose from:
- Strong consistency is the strictest type of consistency available in CosmosDB. The data is synchronously replicated to all the replicas in real-time. This mode of consistency is useful for applications that cannot tolerate any data loss in case of downtime.
- In the Bounded Staleness level, data is replicated asynchronously with a predetermined staleness window defined either by numbers of writes or a period of time. The reads query may lag behind by either a certain number of writes or by a pre-defined time period. However, the reads are guaranteed to honor the sequence of the data.
- Session consistency is the default consistency that you get while configuring the cosmos DB account. This level of consistency honors the client session. It ensures a strong consistency for an application session with the same session token.
- Consistent prefix model is similar to bounded staleness except, the operational or time lag guarantee. The replicas guarantee the consistency and order of the writes however the data is not always current. This model ensures that the user never sees an out-of-order write.
- Eventual consistency is the weakest consistency level of all. The first thing to consider in this model is that there is no guarantee on the order of the data and also no guarantee of how long the data can take to replicate. As the name suggests, the reads are consistent, but eventually.

Use Cases
Any web, mobile, gaming, and IoT application that needs to handle massive amounts of data, reads, and writes at a global scale with near-real response times for a variety of data will benefit from Cosmos DB’s guaranteed high availability, high throughput, low latency, and tunable consistency. The Microsoft Docs article here describes the common use cases for Azure Cosmos DB.
Conclusion
And thats a look at the different options avaiable in Azure Cosmos DB. Hope you enjoyed this post, until next time!