Its Day 90 of my 100 Days of Cloud journey and in this post I’ll be taking a looks at the benefits and architecture of Azure Virtual Desktop.

In the last post we touched briefly on Azure Virtual Desktop in comparison to Windows 365 Cloud PC. Both solutions allow you to easily support accessibility for users, on any device, from anywhere. However while Windows 365 Cloud PC can be easily deployed and managed, Azure Virtual Desktop has greater flexibility which leads to a greater management overhead for administrators.
In the next 2-3 posts after this one, we’ll demo how to set up an Azure Virtual Desktop deployment, but first let familiarize ourselves with the benefits, core concepts and architecture.
Benefits of Azure Virtual Desktop
With Azure Virtual Desktop you can:
- Set up a multi-session Windows 10 deployment that delivers a full Windows 10 with scalability.
- Virtualize Microsoft 365 Apps for enterprise and optimize it to run in multi-user virtual scenarios.
- Provide Windows 7 virtual desktops with free Extended Security Updates.
- Bring your existing Remote Desktop Services (RDS) and Windows Server desktops and apps to any computer.
- Virtualize both desktops and apps.
- Manage Windows 10, Windows Server, and Windows 7 desktops and apps with a unified management experience.
- Bring your own image for production workloads.
- Use autoscale to automatically increase or decrease capacity based on time of day, specific days of the week, or as demand changes, helping to manage cost.
Core Concepts and Hierarchy
Before we jump into the Demo, lets take a quick look at some of the key concepts of Azure Virtual Desktop and where they each sit in the hierarchy of an Azure Virtual Desktop architecture.
Host Pools
Host pools are a collection of one or more identical virtual machines within Azure Virtual Desktop tenant environments. Each host pool can be associated with multiple RemoteApp groups, one desktop app group, and multiple session hosts. Host Pools can be one of two types:
- Personal, where each session host is assigned to individual users.
- Pooled, where session hosts can accept connections from any user authorized to an application group within the host pool. You can set additional properties on the host pool to change its load-balancing behavior, how many sessions each session host can take, and what the user can do to session hosts in the host pool while signed in to their Azure Virtual Desktop sessions. You control the resources published to users through application groups.
There is no limit to the number of pools, and these can be easily scaled either manually or automatically allowing you to add or reduce capacity based on demand which can help manage costs.
Application Groups
An Application group is a logical grouping of applications installed on session hosts in the host pool. An application group can be one of two types:
- RemoteApp, where users access the RemoteApps you individually select and publish to the application group.
- Desktop, where users access the full desktop By default, a desktop application group (named “Desktop Application Group”) is automatically created whenever you create a host pool. You can remove this application group at any time. However, you can’t create another desktop application group in the host pool while a desktop application group already exists. To publish RemoteApps, you must create a RemoteApp application group. You can create multiple RemoteApp application groups to accommodate different worker scenarios. Different RemoteApp application groups can also contain overlapping RemoteApps.
Workspaces
A workspace is a logical grouping of application groups in Azure Virtual Desktop. Each Azure Virtual Desktop application group must be associated with a workspace for users to see the remote apps and desktops published to them.
End users
After you’ve assigned users to their application groups, they can connect to a Azure Virtual Desktop deployment with any of the Azure Virtual Desktop clients.
The diagram below is a typical Azure Virtual Desktop Architecture:

Components – Microsoft Managed versus Customer Managed
We’ve all seen the “as a service” model which is used sometimes to explain what services Microsoft manages versus what a customer managed across IAAS, PAAS and SAAS offerings.
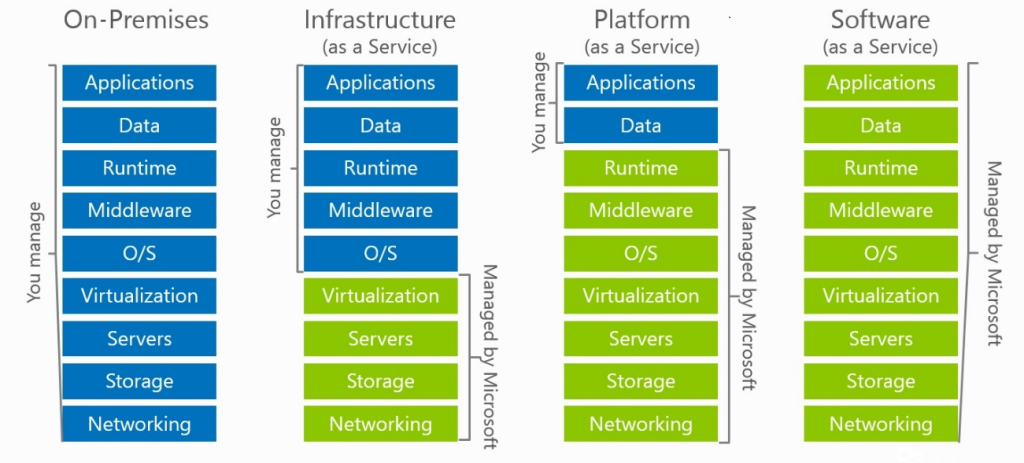
Azure Virtual Desktop is no different in that some of the components of the service are managed by Microsoft and some are required be be managed by the customer. Lets do a quick breakdown of these.
Microsoft Managed
Microsoft manages the following Azure Virtual Desktop services, as part of Azure:
- Web Access Service: allows users access virtual desktops and remote apps through a web browser from anywhere on any device. You can secure Web Access using multifactor authentication in Azure Active Directory.
- Remote Connection Gateway Service: allows remote users to connect to Azure Virtual Desktop apps and desktops from any internet-connected device that can run an Azure Virtual Desktop client. The client connects to a gateway, which then orchestrates a connection from a VM back to the same gateway.
- Connection Broker Service: service manages user connections to virtual desktops and remote apps. The Connection Broker provides load balancing and reconnection to existing sessions.
- Remote Desktop Diagnostics: event-based aggregator that marks each user or administrator action on the Azure Virtual Desktop deployment as a success or failure. Administrators can query the event aggregation to identify failing components.
- Extensibility or Management: Azure Virtual Desktop includes several extensibility components. You can manage Azure Virtual Desktop using Windows PowerShell or with the provided REST APIs, which also enable support from third-party tools.
Customer Managed
Customers manage these components of Azure Virtual Desktop solutions:
- Azure Virtual Network: allows Azure resources like VMs communicate privately with each other and with the internet. You can enforce your organizations policies by connecting Azure Virtual Desktop host pools to an Active Directory domain. You can connect an Azure Virtual Desktop to an on-premises network using a virtual private network (VPN), or use Azure ExpressRoute to extend the on-premises network into the Azure cloud over a private connection.
- Identity – there are 2 options for authentication against Azure Virtual Desktop:
- Azure Active Directory: Azure Virtual Desktop uses Azure AD for identity and access management. Azure AD integration applies Azure AD security features like conditional access, multi-factor authentication, and the Intelligent Security Graph, and helps maintain app compatibility in domain-joined VMs.
- Active Directory Domain Services: Azure Virtual Desktop VMs must domain-join an AD DS service, and the AD DS must be in sync with Azure AD to associate users between the two services. You can use Azure AD Connect to associate AD DS with Azure AD.
- Azure Virtual Desktop session hosts: A host pool can run the following operating systems:
- Windows 7 Enterprise
- Windows 10 Enterprise
- Windows 10 Enterprise Multi-session
- Windows Server 2012 R2 and above
- Custom Windows system images with pre-loaded apps, group policies, or other customizations
- Azure Virtual Desktop Workspace: this is used to manage and publish host pool resources.
As I also touched briefly on in the last post, you also have the option to host your Azure Virtual Desktop environment locally on an on-premises Azure Stack HCI infrastructure. This however is still in preview, and you can find more details here.
Conclusion
Thats a high-level overview of the benefits and concepts of Azure Virtual Desktop. You can find the full details of how it works in the official Microsoft Documentation here. In the next post, we’ll start our Demo build of an AVD environment!
Hope you enjoyed this post, until next time!